
The LLM Proposes. The System Enforces.
If a decision matters and it recurs, chat is the wrong operating environment.
That is not an argument against AI. It is an argument against running payables, routing, review queues, and exception handling through browser tabs and chat history. Chat is excellent for exploration. It is a poor place to operate anything where the same decision needs to happen the same way next week.
The basic trade is simple: chat gives you outputs. Systems give you ROI.
The business question
Every business that receives invoices faces the same recurring decision: read the document, pull out the fields that matter, and either approve the numbers or send them to a human.
The stakes are concrete. Get one total wrong and you overpay or delay payment. Get the vendor wrong and you chase the wrong counterparty. Get the line items wrong and downstream reconciliation breaks.
The business question is: can you extract structured invoice data reliably enough to act on it—without depending on whoever remembered the magic prompt that day?
Chat fails this test for a boring reason. It is not reproducible, not versioned, and not really auditable. Different people ask slightly different questions in slightly different contexts and get slightly different answers. If the process only works when Sarah remembers the prompt, you do not have AI capability. You have Sarah.
In operations, that does not show up as a philosophical problem. It shows up as different answers for the same decision—and that is how money leaks.
The pattern: one narrow loop
The alternative is not an enterprise AI strategy, a foundation model, or a twenty-person task force. It is one narrow loop:
- One recurring decision
- One owner
- One schema
- One pipeline
- One set of tests
If you can make one recurring decision cheaper, faster, and more consistent, that is where the ROI actually comes from. The pattern scales by repetition, not by ambition.
Worked example: invoice extraction
Invoices are a useful anchor because the problem is narrow, the stakes are real, and the failure modes are familiar. PDFs arrive from different vendors in different layouts—some digital, some scanned. The recurring decision is always the same: extract vendor, date, and line items into a structure the business can validate and act on.
The point of the system is not extraction for its own sake. The point is preventing bad decisions from hitting your cash.
The LLM proposes the fields. The system validates them. Bad outputs go to review. Every run is logged so the decision can be replayed.
That is the whole pattern: the LLM proposes; the system enforces.
How it works
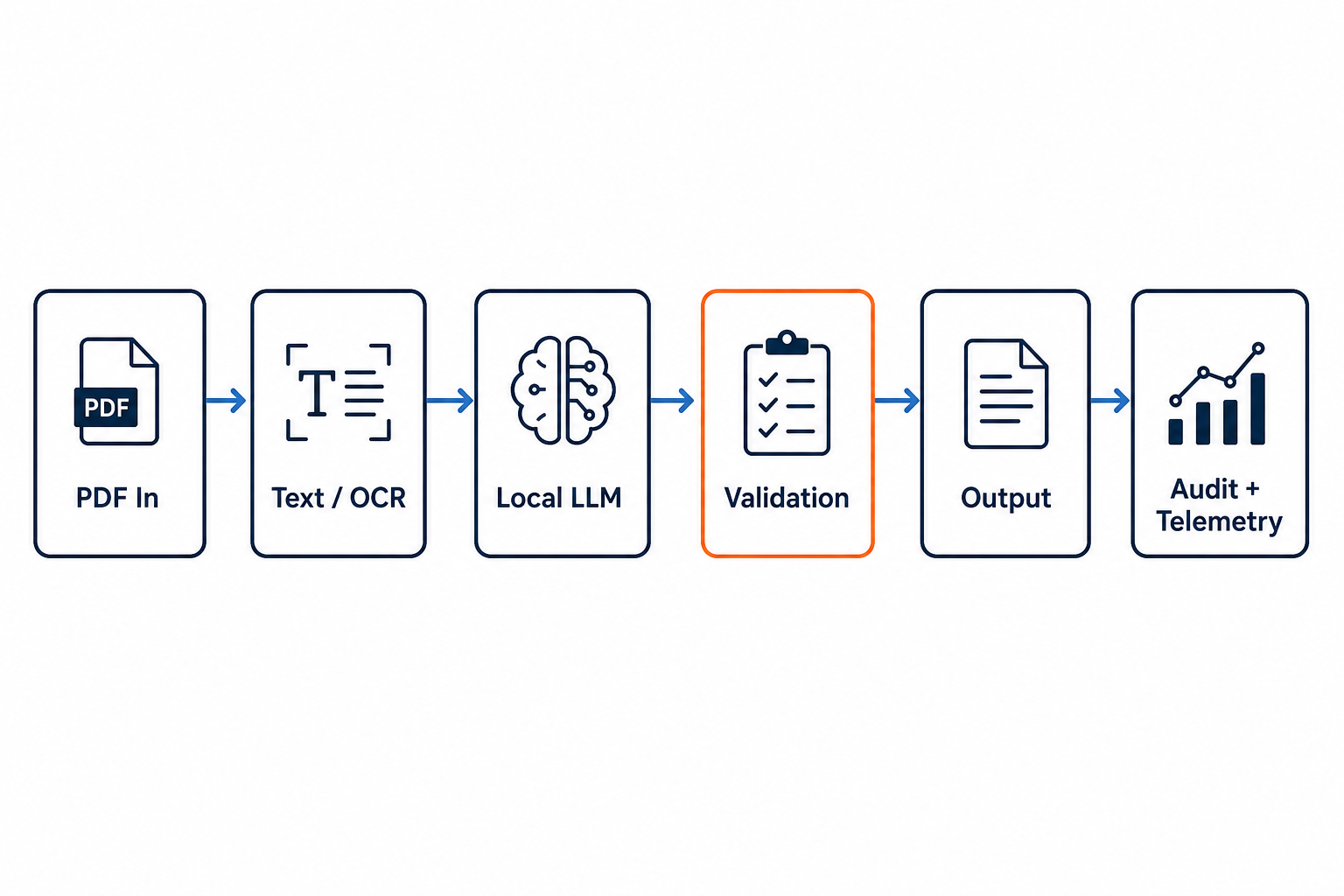
This example runs fully offline on a laptop. A local model (via Ollama) proposes structured fields; validation and the pipeline enforce correctness. Nothing leaves the machine.
PDF in
→ text extract (with OCR fallback for scanned pages)
→ local LLM proposes structured fields
→ validation checks schema and business rules
→ output (ok) or escalation (needs_review)
→ telemetry + audit bundle written for every document
Each document produces three kinds of artifacts:
- Results JSON — final extraction and status (
ok,needs_review, orerror) - Audit bundle — replayable record per document: extracted text, exact prompt, raw model output, validation outcome, final decision
- Telemetry log — append-only trace of every stage, timing, retries, and model parameters
If you cannot replay the decision, you cannot defend it. The audit bundle exists so a reviewer can see exactly what the model saw, what it returned, and why the system accepted or rejected it—without opening a chat thread that no longer exists.
A typical run looks like this in the terminal:
Request a1b2c3d4 (invoice_acme.pdf)
+ extract (text,ocr)
+ llm (3 extraction(s))
! validation (extraction 2: amount is required)
+ retry (attempt 2)
+ llm (3 extraction(s))
+ validation
=> ok
The model got it wrong on the first pass. The system caught it and retried. That is test-driven design for AI—not unit-testing the weights, but testing the system around the model.
Governance layers
The model is not trusted on its own. It is constrained by layers the business owns:
| Layer | What it does | Invoice example |
|---|---|---|
| Schema | Define the shape of valid output | Vendor, date, line items with required amounts |
| Validation | Reject proposals that fail rules | Missing amount → retry or flag |
| Escalation | Route uncertainty to humans | needs_review instead of guessing |
| Telemetry | Log every step for replay | Per-document trace, audit bundle |
| Monitoring | Detect drift over time | Validation rates, retry counts, model version |
The question is not “does the model work?” It is “can we defend this decision?” A model you cannot validate is not innovation. It is unmanaged risk.
Results from a real batch
I ran this pipeline against eight real-world contractor invoices—HVAC, roofing, drainage, gutters, flooring, foundation work. Different vendors, different layouts, no templates. One local model, one prompt version, one validation schema.
| Document | Output | Vendor | Total |
|---|---|---|---|
| floor.pdf | ok | Footprints Floors Operations | $4,873.50 |
| Invoice #124993.pdf | ok | Mr. Handyman of Birmingham | $1,272.00 |
| drainage.pdf | needs_review | BDry Alabama | $3,420.90 |
| foundation.pdf | needs_review | AFS Newco, LLC | $5,949.00 |
| Invoice #896007.pdf | needs_review | Mister Sparky | $200.00 |
| Invoice-0001008.pdf | needs_review | Jesse Humphreys / Bama Gutters | $15,788.00 |
| roof.pdf | needs_review | Fleming Roofing and Restoration | — |
| AP HVAC Contract 1.pdf | needs_review | — | — |
Two ran clean end to end. Six were flagged needs_review—not because the pipeline failed, but because validation caught something the model could not resolve with confidence: a missing date, a line item without an amount, a contract layout that did not fit the invoice schema.
That refusal is not a weakness. That refusal is the feature.
When the model fails, it does not silently pass a bad number downstream. The system catches it, retries where configured, or marks the document for human review. In payables, a flagged exception is infinitely better than a confident wrong total.
What this is—and is not
This is not an argument to stop using chat. Draft the email. Explore the idea. Make the poster. Fine.
This is not a product pitch. Invoices are the anchor; the governance wrapper is the point. The same propose → validate → log → audit pattern applies anywhere a recurring decision needs to be cheaper, faster, and more consistent.
This is not a call to train a foundation model. A small local model on existing hardware, wrapped in validation and logging, is often good enough for a narrow, closed task—and the validation layer turns “good enough” into “trustworthy.”
Who should care
Anyone running a recurring decision through chat history when the stakes are real:
- Accounts payable — invoice intake, three-way match prep, exception routing
- Operations leaders — any process where inconsistent answers create rework, delays, or cash leakage
- Owners of “Sarah’s prompt” — if one person’s memory is the system of record, you have a staffing risk dressed up as AI
The actionable next step is smaller than an AI strategy. Pick one messy, expensive, recurring process. Write down exactly what has to happen. Write down what would have to be true for you to trust it. Then build one monitored loop around it.
Name the decision. Name the owner. Define the tests. Log the run. Monitor the failures. Make the decision replayable.
A prompt is not a process. A clever chat session is not a decision engine.
The LLM proposes. The system enforces. That is the difference between playing with AI and operating with it.
If a recurring decision is still living in someone’s chat history, start with a 45-minute Data & Operations Audit